Can random molecular interactions create life? (Origins Debate: Part I)
Part I in the series: Highlights of the Los Alamos Origins Debate
John R. Baumgardner, Ph.D. Asides and media by Nicholas Petersen
Many evolutionists are persuaded that the 15 billion years they assume for the age of the cosmos is an abundance of time for random interactions of atoms and molecules to generate life. A simple arithmetic lesson reveals this to be no more than an irrational fantasy.1
This arithmetic lesson is similar to calculating the odds of winning the lottery. The number of possible lottery combinations corresponds to the total number of protein structures (of an appropriate size range) that are possible to assemble from standard building blocks. The winning tickets correspond to the tiny sets of such proteins with the correct special properties from which a living organism, say a simple bacterium, can be successfully built. The maximum number of lottery tickets a person can buy corresponds to the maximum number of protein molecules that could have ever existed in the history of the cosmos.

Let us first establish a reasonable upper limit on the number of molecules that could ever have been formed anywhere in the universe during its entire history. Taking 1080 as a generous estimate for the total number of atoms in the cosmos2, 1012 for a generous upper bound for the average number of interatomic interactions per second per atom, and 1018 seconds (roughly 30 billion years) as an upper bound for the age of the universe, we get 10110 as a very generous upper limit on the total number of interatomic interactions which could have ever occurred during the long cosmic history the evolutionist imagines. Now if we make the extremely generous assumption that each interatomic interaction always produces a unique molecule, then we conclude that no more than 10110 unique molecules could have ever existed in the universe during its entire history.
Now let us contemplate what is involved in demanding that a purely random process find a minimal set of about one thousand protein molecules needed for the most primitive form of life. To simplify the problem dramatically, suppose somehow we already have found 999 of the 1000 different proteins required and we need only to search for that final magic sequence of amino acids which gives us that last special protein. Let us restrict our consideration to the specific set of 20 amino acids found in living systems and ignore the hundred or so that are not. Let us also ignore the fact that only those with left-handed symmetry appear in life proteins. Let us also ignore the incredibly unfavorable chemical reaction kinetics involved in forming long peptide chains in any sort of plausible non-living chemical environment.
What is a protein

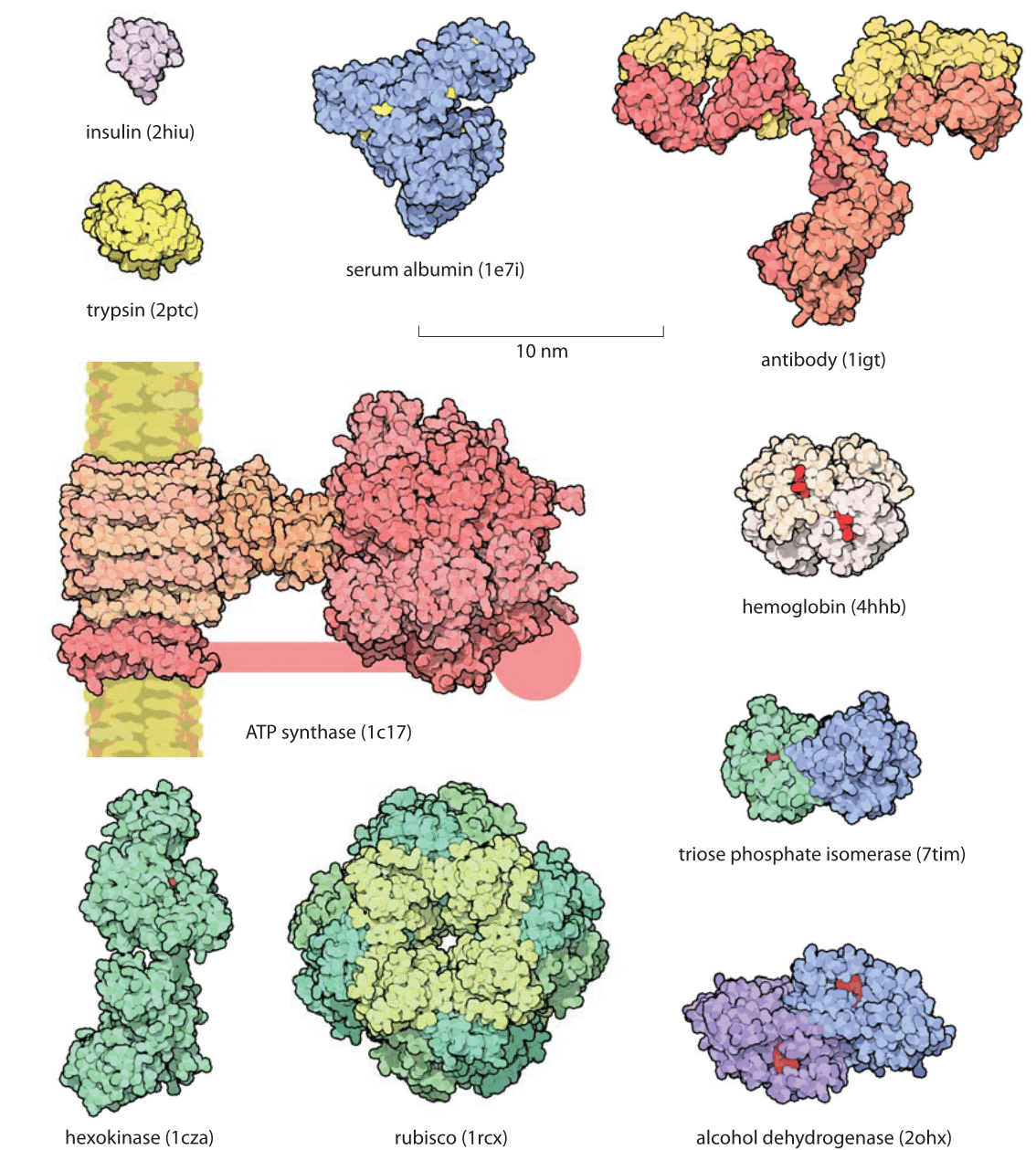
If you are not a biology type person, you may be wondering at this point: What’s all of this to-do about ‘proteins’? Proteins are a whole lot more than simply a nutritional substance we get from eating meat! Simply put, proteins perform functions in the cell, and in fact proteins “participate in virtually every process within cells” (“Protein”). Proteins can even become so complex that they must be categorized as nothing less than micro-machines, and even as micro-motors. Below we will consider just two examples of such molecular / protein machines. The cell is nothing without its myriad of diverse proteins. You might say that a cell (the foundation of biological life) without proteins, would be like an ant-colony without ants. Here, Dr. Baumgardner is computing the odds of just a single (useful) protein arising by chance, even though the simplest functioning cell would need many hundreds of such highly-specified proteins working together in order to exist in the first place.
Let us merely focus on the task of obtaining a suitable sequence of amino acids that yields a 3D protein structure with some minimal degree of essential functionality. Various theoretical and experimental evidence indicates that in some average sense about half of the amino acid sites must be specified exactly3. For a relatively short protein consisting of a chain of 200 amino acids, the number of random trials needed for a reasonable likelihood of hitting a useful sequence is then on the order of 20100 (100 amino acid sites with 20 possible candidates at each site), or about 10130 trials. This is a hundred billion billion times the upper bound we computed for the total number of molecules ever to exist in the history of the cosmos!! No random process could ever hope to find even one such protein structure, much less the full set of roughly 1000 needed in the simplest forms of life. It is therefore sheer irrationality for a person to believe random chemical interactions could ever identify a viable set of functional proteins out of the truly staggering number of candidate possibilities.
Let’s unpack this critical paragraph:
“Various theoretical and experimental evidence indicates that in some average sense about half of the amino acid sites must be specified exactly.” - This is a critical point upon which the calculation depends. Note that it’s extremely difficult to calculate the odds of something like this, because there seems to be almost “infinite” possible variations one could imagine, in this case, of protein letter sequences and of the structure that arises from them. But without looking at the source of this claim, it’s basically saying: Sure, there seem to be infinite possibilities, but let’s work backwards and look at the myriads of proteins that do exist: What percentage of letters in these proteins must be exactly specified in order for them to still function? As we’ll see below, plenty of times simply messing with just one letter in the protein will cause major disease and disfunction, so that helps us to understand that yes, indeed, a large portion, certainly half, of the letters in any given protein, must be specified exactly in order for it to be functional.
“For a relatively short protein consisting of a chain of 200 amino acids…” - See here to get an idea on the average size of proteins. If I am reading the evidence correctly, the median size of a protein in humans is 431, and 277 in E. Coli. So while there are plenty of proteins 200 amino acids in length, this is still less than the median length, and many proteins are much larger than this.
“For a relatively short protein consisting of a chain of 200 amino acids, the number of random trials needed for a reasonable likelihood of hitting a useful sequence is then on the order of 20100…” Let’s elaborate: If half of the letters must be exactly specified in any functional protein, then to happen by pure chance upon one such useful protein that is 200 letters in length, could be calculated by simply requiring half of it’s letters = 100, come into arrangement by chance. Since there are 20 amino acid letters to choose from, the odds of this is simply 20100. (20 [letters] times itself 100 times = 20 x 20 x 20 x 20 … 100 times altogether). By comparison, the odds of you getting an exactly specified sequence of 4 dice rolls (let’s say of [ 3, 1, 5, 3 ]) is 64. The odds of getting an exact sequence of 100 dice rolls would be 6100 which roughly equals 6 with 77 zeros behind it. But a dice only had 6 possibilities, the amino acids in this case have 20 possibilities per turn.
In the face of such stunningly unfavorable odds, how could any scientist with any sense of honesty appeal to chance interactions as the explanation for the complexity we observe in living systems? To do so, with conscious awareness of these numbers, in my opinion represents a serious breach of scientific integrity. This line of argument applies, of course, not only to the issue of biogenesis but also to the issue of how a new gene/protein might arise in any sort of macroevolution process.
One retired Los Alamos National Laboratory Fellow, a chemist, wanted to quibble that this argument was flawed because I did not account for details of chemical reaction kinetics. My intention was deliberately to choose a reaction rate so gigantic (one million million reactions per atom per second on average) that all such considerations would become utterly irrelevant. How could a reasonable person trained in chemistry or physics imagine there could be a way to assemble polypeptides on the order of hundreds of amino acid units in length, to allow them to fold into their three-dimensional structures, and then to express their unique properties, all within a small fraction of one picosecond!? Prior metaphysical commitments forced him to such irrationality.
Another scientist, a physicist at Sandia National Laboratories, asserted that I had misapplied the rules of probability in my analysis. If my example were correct, he suggested, it “would turn the scientific world upside down.” I responded that the science community has been confronted with this basic argument in the past but has simply engaged in mass denial. Fred Hoyle, the eminent British cosmologist, published similar calculations two decades ago.4 Most scientists just put their hands over their ears and refused to listen.
In reality this analysis is so simple and direct it does not require any special intelligence, ingenuity, or advanced science education to understand or even originate. In my case, all I did was to estimate a generous upper bound on the maximum number of chemical reactions – of any kind – that could have ever occurred in the entire history of the cosmos and then compare this number with the number of trials needed to find a single life protein with a minimal level of functionality from among the possible candidates. I showed the latter number was orders and orders larger than the former. I assumed only that the candidates were equally likely. My argument was just that plain. I did not misapply the laws of probability. I applied them as physicists normally do in their every day work.
Why could this physicist not grasp such trivial logic? I strongly believe it was because of his tenacious commitment to atheism that he was willing to be dishonest in his science. At the time of this editorial exchange, he was also leading a campaign before the state legislature to attempt to force this fraud on every public school student in our state.
In the discussion above, Dr. Baumgardner made the following statement with regard proteins and the odds of their (hypothetical) chance formation:
Let us merely focus on the task of obtaining a suitable sequence of amino acids that yields a 3D protein structure with some minimal degree of essential functionality. Various theoretical and experimental evidence indicates that in some average sense about half of the amino acid sites must be specified exactly.
One does not need to be a microbiologist to see that allowing half of the building blocks of the protein to be something else, while allowing that protein to still function, is being generous. It is hard to imagine the pictured proteins functioning as they do if much at all of their protein sequences were to be altered (think of the specificity exhibited in the ATP Sythase’s crankshaft / motor complex, as we will see pictured below). Furthermore, the following considerations show that even very minor changes in protein structures, even changes of just one amino acid (analogous to changing just one letter within a paragraph), can be utterly devastating to the protein’s function:
Small Errors in Proteins Can Cause Disease: Sometimes, an error in just one amino acid can cause disease. Sickle cell disease … is caused by a single error in the gene for hemoglobin, the oxygen-carrying protein in red blood cells. This error, or mutation, results in an incorrect amino acid at one position in the molecule. Hemoglobin molecules with this incorrect amino acid stick together and distort the normally smooth, lozenge-shaped red blood cells into jagged sickle shapes. … Another disease caused by a defect in one amino acid is cystic fibrosis. … The disease is caused when a protein called CFTR is incorrectly folded. This misfolding is usually caused by the deletion of a single amino acid in CFTR.
Chaperonin Protein Complex
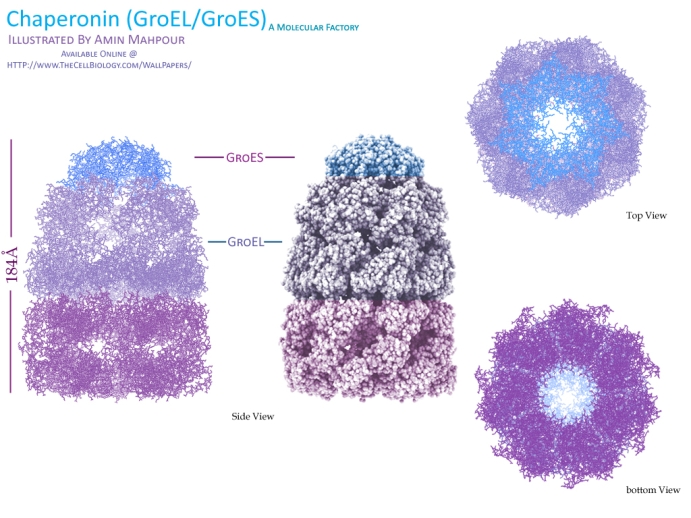
Consider Brian Thomas’ description of the wonder that is the Chaperonin:
… A molecular example is found in chaperonins. In cells, these barrel-shaped protein complexes shelter certain other proteins from watery environments, giving them extra time to fold into their necessary shapes. Chaperonins have a precisely-placed enzymatic active site, detachable caps, flexible gated entryways, a timed sequence of chemical events, and precise expansion and flexion capacities. Each of the parameters – size, shape, strength, hydrophobicity distribution, timing, and sequence—represents a specification. With each additional specification, the likelihood of a chance-based assembly of these parts diminishes…to miracle status.5
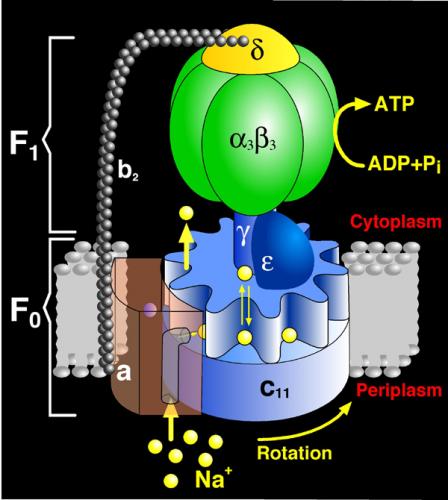
ATP Synthase — ‘Your own personal power plant’
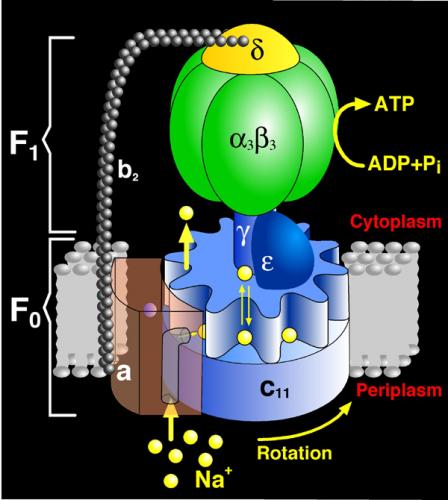{kind=link}
A fascinating discussion of this remarkable molecular motor can be found here:
“Energy in the body comes from millions and millions of tiny power generators, each equipped with a crankshaft that spins round and round 24/7, producing the fuel that makes us go. … Right. And the moon is made of Gouda cheese. – Suspend your disbelief. The protein adenosine triphosphate synthase, better known as ATPase, is nature’s smallest rotary motor. “You can take a spoonful of that protein,” says biophysicist Klaus Schulten of the University of Illinois Urbana-Champaign, “and it generates as much torque as a Mercedes engine.” … Probably the most abundant protein in all living organisms, ATPase is the power plant of metabolism. – The Wheel Spins Round and Round – Like most motors, ATPase has moving and non-moving parts. There’s a wheel that spins, similar to a millwheel, to turn an axle that revolves inside a hexagonal cluster, in which there are three combustion chambers (active sites), each of which, in sequence, charges up with chemical raw materials — adenosine diphosphate (ADP) and phosphate — and “fires” to produce ATP.”
Footnotes
Featured image of the DNA Double Helix Molecule originally from here (now obsolete), from Darwin’s Theory of Evolution: DNA Causes Geneticists, Other Scientists, Join Ranks of Dissenters (April 6, 2009).↩︎
C. W. Allen, Astrophysical Quantities 3rd Ed., University of London, Athlone Press, p. 293, 1973; M. Fukugita, C. J. Hogan, and P. J. E. Peebles, “The Cosmic Baryon Budget,” Astrophys. J., 503, 518-530, 1998.↩︎
H. P. Yockey, “A Calculation of the Probability of Spontaneous Biogenesis by Information Theory,” Journal of Theoretical Biology, 67, 377-398, 1978; Information Theory and Molecular Biology, Cambridge University Press, 1992.↩︎
F. Hoyle and N. C. Wickramasinghe, Evolution From Space, J. M. Dent, London, 1981.↩︎
Brian Thomas, M.S., ““More Than Just ‘Complex’,” Acts & Facts 12(2008), p. 15↩︎
{kind=link}